The Date that wasn’t
A tale of lakes, dates and random results. Recently, I was working on a data project for a client that required diving into their data lake. The last time I worked for this client, there was no data lake, so I just took everyone at face value when it was suggested we use the lake to get the data we need. I’ve had quite a significant amount of experience working with data lakes in the past few years, and the client is a modern company, so I didn’t expect any issue. This is the same client that made me dust off my JVM and Scala setup. The data itself is event based, and spans about a decade. For the sake of visualisation, let’s say that the events tracked visitors entering and exiting an amusement park. Pure events can be tricky to work with in the real world, so we wanted to give the business daily aggregations. Two tables that were of interest to us for this project were The lake itself is partitioned by date, so there’s an extra virtual column that appears in the tables as We got to work and started writing some ETLs to get the required data. As a first draft, I quickly wrote a SQL query that could be run on Athena to give us the data we needed: Note: Neither the data nor the queries are directly lifted from my client—I’m just retyping from memory and trying to make it easier to grok. Some of these queries or code might not be working exactly as is, but I hope it helps explain what we were doing. After running the query, we knew something was quite wrong: on some days we had a negative number of visitors. I double checked the query, talked to the business to understand the behaviour of their visitors, and everything was supposed to check out. We also checked non-negative days to see what the potentially normal days were like. They were all completely wrong. I started digging more into the data. Because the dataset was reasonably large, I started scoping down—instead of working on a whole year, I started looking month by month, but I couldn’t find a specific pattern that made sense. While on a call with the other two engineers working on this, we weren’t sure how long it took for events to replicate to the lake, so I ran a query to get the most recent partition: Blink. I wrote that query around the end of April 2025, so seeing a date over a month in the future was a bit of a shock. Was this lake actually tracking time travellers? Obviously not, so something had to be going on. I started digging in, and specifically looked at the single event registered to this date. Its So we started looking into the system that was writing these items to the lake. The system itself was a Kafka consumer written in Scala. All three of us started poring over the code, but we couldn’t see anything wrong. I obviously can’t share the actual code here, but in essence, each Kafka message was an Avro record. The service decoded each record, enriched it with a bit of metadata, and then wrote the entire thing to the lake as a Parquet file. Fairly unsurprising stuff. In pseudocode: Did you catch it? I didn’t. It didn’t even occur to me in the least. I even talked about it with a friend, and we went over the documentation of To be fair, it’s really well hidden, unless you know what to look for. It’s a class of problems I had frankly almost forgotten about in the last few years, simply because I’ve been using languages that don’t really have this kind of problem anymore. I was so sure the problem came from the I thought that somehow, we were getting a weird value from the Avro message producers that was causing the formatter to go haywire. In hindsight, it pains me to write down that this was where my mind went, as it is a painfully obvious mistake. My brain kept hitting the same wall: if We started grepping through the codebase, trying to find any producer that was generating these Avro messages to see how they were initialising I downloaded all the mispartitioned events in the lake1, and started analysing the During this analysis, I discovered an even weirder thing: some of the The issue was discovered late on Friday. We were digging through all the potential problems and sifting through the data for a couple days. All of a sudden, Joana—one of the two brilliant engineers working with me on this—asked: “what if it’s a thread safety problem?” We all stared at one another in stunned silence for a few seconds. My mind started racing: are there thread unsafe parts in the Java standard library? How parallel is this code that writes to the lake? How many pods are running? This is not a critical service, so unless it’s under very high load, only one pod will run. Joana showed us what she was looking at: the code that reads the messages off the wire and feeds them into the record transformer. It was using a parallel iterator to handle a bunch of messages simultaneously. A few seconds later, we saw the warning in the legacy It explained everything. The system could handle messages that weren’t exclusively instant. There was backfilling happening, so we could continuously receive messages from months or years in the past. Whenever multiple messages were handled together, the But because no message ever wrote 2026 onto the year part, even the thread-unsafe formatter couldn’t invent that. Within minutes a fix was deployed. We had a bunch of logging that showed the severity of the problem. We still have a slightly polluted lake to clean up, but at least we know there’s only clean streams flowing into it. Do yourself a favour: grep your codebase for admissions and exits. Both tables had exactly the same schema:creation_time: an ISO 8601-style UTC timestamp of when the event was generatedcompany_id: UUID4, the company a visitor is affiliated with, if anyvisitor_id: UUID4 uniquely identifying the visitordt which is a string (due to HDFS partitions being part of the file path) representing a specific date (for example: 2021-02-03).SELECT
dt,
SUM(delta) AS visitors
FROM (
SELECT
dt,
company_id,
1 AS delta
FROM admissions
WHERE dt BETWEEN '2021-01-01' AND '2021-12-31'
UNION ALL
SELECT
dt,
company_id,
-1 AS delta
FROM exits
WHERE dt BETWEEN '2021-01-01' AND '2021-12-31'
) AS combined
GROUP BY dt, company_id
ORDER BY dt;
> SELECT MAX(DATE(dt)) FROM admissions;
'2025-05-27'
creation_time was 2025-04-11T13:08:51.000Z, or about two weeks prior to when I was investigating this, but was otherwise unremarkable. Unremarkable, save for the fact that two columns of the same row completely contradicted one another.
SimpleDateFormat and we didn’t notice it.asInstanceOf line I even wrote this in the group chat: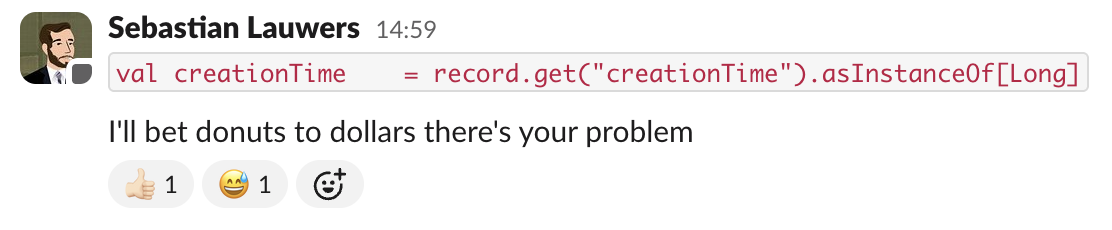
dt and creationTime are based on the same value, how can dt end up being completely different?creationTime. Most were using Instant.now, some were truncating the millis, some were even truncating at the second level. Could there be something going where instead of zeroing the least significant digits they were instead shifting the int to the right? But that would only cause dates in the past, nothing in the future. We found nothing truly odd in the message producers.dt column. Here are a few screenshots from my analysis with xan2.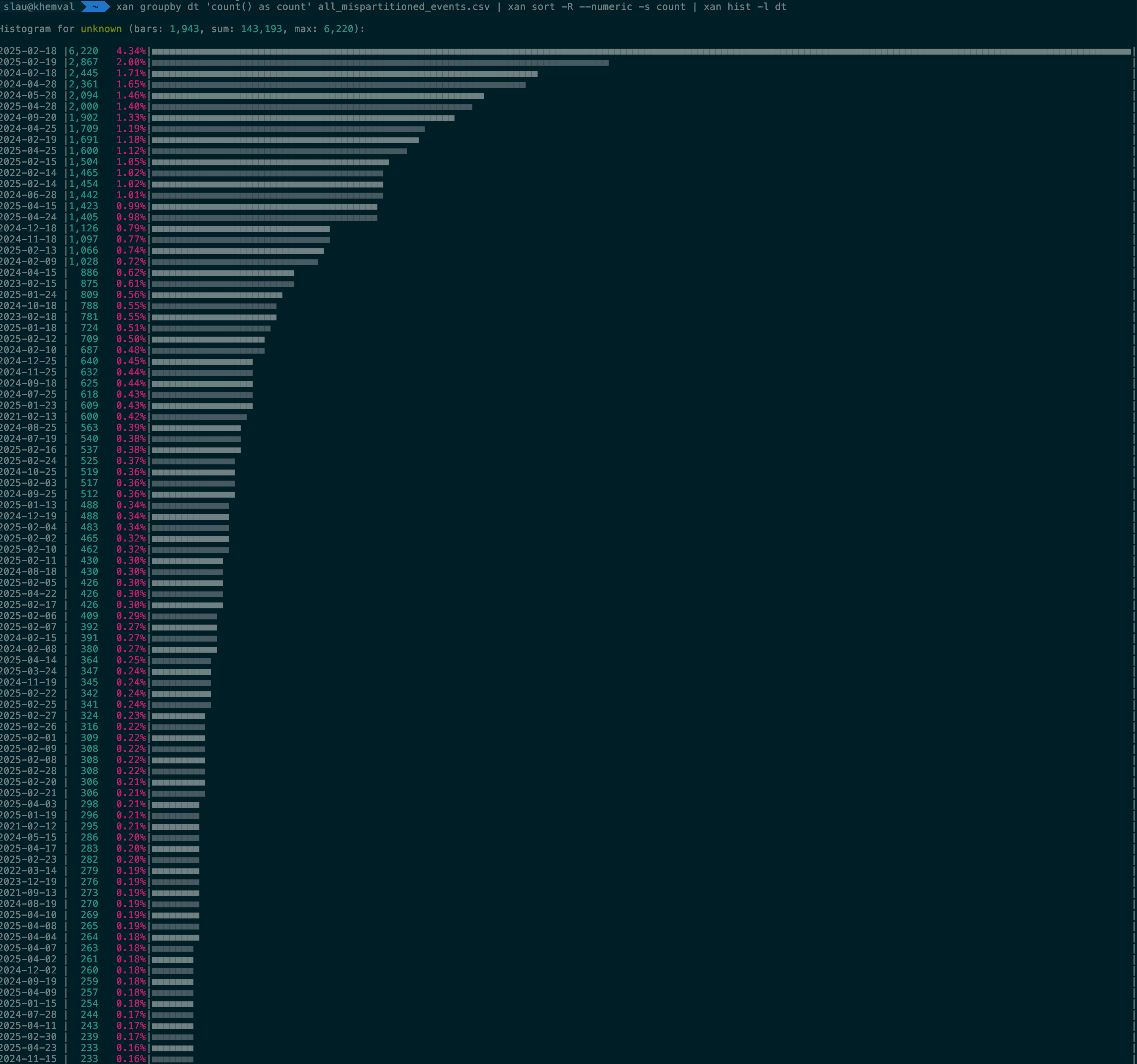
dt values were invalid dates. The first one I spotted was 2024-09-31. The next ones were more usual suspects: 2025-02-29, 2025-02-30 and 2025-02-31, same for 2024. How could a battle-tested Java library be generating invalid dates? Another odd thing is that we had dates all over 2025 and before, but there was a hard stop on 2025-12-31. Nothing beyond it.java.text.SimpleDateFormat documentation that it is not thread safe. The comparatively modern java.time.format.DateTimeFormatter is.dt would get botched in a way that only thread-unsafety does. One message in late 2024 and one in early 2025 might partition the events in late 2025. A message from the 31 August and another from 2 September might end up partitioned into 31 September. Same for February.java.text.SimpleDateFormat.